Stable Diffusion 2.0 жқҘдәҶ-дё–з•ҢжҠҘйҒ“
Stable Diffusion дёҖз»ҸеҸ‘еёғпјҢе°ұз«ӢеҲ»еңЁдёҡз•ҢжҺҖиө·е·ЁеӨ§зҡ„жіўжөӘгҖӮжҲ‘дёӘдәәеҗҺзҹҘеҗҺи§үпјҢзӣҙеҲ° Stable Diffusion V1.4 зүҲжң¬еҸ‘еёғпјҢжүҚжҺҘи§Ұ Stable Diffusion (д№ӢеүҚдҪҝз”Ёзҡ„жҳҜ Disco Diffusion)гҖӮиҝҷж®өж—¶й—ҙпјҢSD еӣўйҳҹд№ҹжІЎй—ІзқҖпјҢеҫҲеҝ«е°ұеҸ‘еёғдәҶ V2 зүҲжң¬гҖӮдёӢйқўзңӢзңӢ SD V2 зүҲжң¬з»ҷжҲ‘们еёҰжқҘдәҶе“ӘдәӣжғҠе–ңгҖӮ
 (зӣёе…іиө„ж–ҷеӣҫ)
(зӣёе…іиө„ж–ҷеӣҫ)
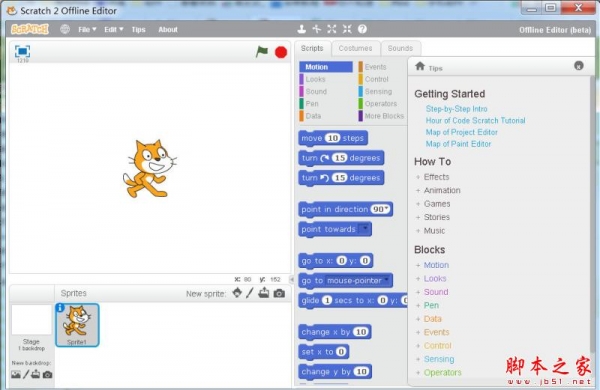
е…Ёж–°зҡ„ж–Үжң¬еҲ°еӣҫеғҸжү©ж•ЈжЁЎеһӢ
Stable Diffusion 2.0 зүҲжң¬еҢ…жӢ¬дҪҝз”Ёе…Ёж–°ж–Үжң¬зј–з ҒеҷЁ (OpenCLIP) и®ӯз»ғзҡ„ејәеӨ§зҡ„ж–Үжң¬еҲ°еӣҫеғҸжЁЎеһӢпјҢиҜҘжЁЎеһӢз”ұ LAION еңЁ Stability AI зҡ„ж”ҜжҢҒдёӢејҖеҸ‘пјҢдёҺж—©жңҹзҡ„ V1 зүҲжң¬зӣёжҜ”еӨ§еӨ§жҸҗй«ҳдәҶз”ҹжҲҗеӣҫеғҸзҡ„иҙЁйҮҸгҖӮжӯӨзүҲжң¬дёӯзҡ„ж–Үжң¬еҲ°еӣҫеғҸжЁЎеһӢеҸҜд»Ҙз”ҹжҲҗй»ҳи®ӨеҲҶиҫЁзҺҮдёә 512x512 еғҸзҙ е’Ң 768x768 еғҸзҙ зҡ„еӣҫеғҸгҖӮ
иҝҷдәӣжЁЎеһӢеңЁ Stability AI зҡ„ DeepFloyd еӣўйҳҹеҲӣе»әзҡ„ LAION-5B ж•°жҚ®йӣҶзҡ„зҫҺеӯҰеӯҗйӣҶдёҠиҝӣиЎҢи®ӯз»ғпјҢ然еҗҺдҪҝз”Ё LAION зҡ„ NSFW иҝҮж»ӨеҷЁиҝӣдёҖжӯҘиҝҮж»Өд»ҘеҲ йҷӨжҲҗдәәеҶ…е®№гҖӮ
жҹҗдәӣдәәеҸҜиғҪдјҡжңүжүҖеӨұжңӣпјҢдёҚиғҪеҶҚдҪҝз”ЁжңҖж–°жЁЎеһӢжқҘз”ҹжҲҗиүІеӣҫдәҶгҖӮ
дёӢйқўжҳҜдҪҝз”Ё Stable Diffusion 2.0 з”ҹжҲҗзҡ„еӣҫеғҸзӨәдҫӢпјҢеӣҫеғҸеҲҶиҫЁзҺҮдёә 768x768гҖӮ
и¶…еҲҶиҫЁзҺҮ Upscaler жү©ж•ЈжЁЎеһӢ
Stable Diffusion 2.0 иҝҳеҢ…жӢ¬дёҖдёӘ Upscaler Diffusion жЁЎеһӢпјҢиҜҘжЁЎеһӢе°ҶеӣҫеғҸзҡ„еҲҶиҫЁзҺҮжҸҗй«ҳдәҶ 4 еҖҚгҖӮдёӢйқўжҳҜдҪҺеҲҶиҫЁзҺҮз”ҹжҲҗеӣҫеғҸ (128x128) ж”ҫеӨ§дёәжӣҙй«ҳеҲҶиҫЁзҺҮеӣҫеғҸ (512x512) зҡ„зӨәдҫӢгҖӮ
е…¶е®һеңЁ V1 зүҲжң¬дёӯпјҢд№ҹеҸҜд»Ҙеј•е…ҘйўқеӨ–зҡ„жӯҘйӘӨиҝӣиЎҢеӣҫеғҸж”ҫеӨ§пјҢжүҖд»ҘиҝҷдёҖйЎ№ж”№иҝӣз®—дёҚдёҠжғҠе–ңгҖӮеҪ“然пјҢзҺ°еңЁеҸҜд»ҘдёҖжӯҘеҲ°дҪҚпјҢStable Diffusion 2.0 еҸҜд»Ҙз”ҹжҲҗеҲҶиҫЁзҺҮдёә 2048x2048 з”ҡиҮіжӣҙй«ҳзҡ„еӣҫеғҸгҖӮ
ж·ұеәҰеӣҫеғҸжү©ж•ЈжЁЎеһӢ
иҝҷдёӘз§°дёә depth2img зҡ„жЁЎеһӢпјҢе®һйҷ…дёҠе°ұжҳҜ V1 д№ӢеүҚзҡ„еӣҫеғҸеҲ°еӣҫеғҸеҠҹиғҪзҡ„еҚҮзә§пјҢд№ҹжҳҜзҺ°еңЁзҪ‘еҸӢзҺ©еҫ—еҫҲе—Ёзҡ„дёҖдёӘеҠҹиғҪпјҢд№ҹе°ұжҳҜдҪҝз”ЁдёҖеј еӣҫзүҮдҪңдёәжҸҗзӨәпјҢз”ҹжҲҗдёҖе№…з»“жһ„зұ»дјјзҡ„дҪңе“ҒгҖӮ
еҰӮдёӢеӣҫжүҖзӨәпјҢе·Ұиҫ№зҡ„иҫ“е…ҘеӣҫеғҸеҸҜд»Ҙдә§з”ҹеҮ дёӘж–°еӣҫеғҸпјҲеҸіиҫ№пјүгҖӮеҸҜд»ҘзңӢеҮәпјҢеҸіиҫ№з”ҹжҲҗзҡ„еӣҫеғҸдҝқжҢҒиҫ“е…ҘеӣҫеғҸзҡ„з»“жһ„е’ҢеҪўзҠ¶пјҢдҪҶеҶ…е®№дёҠеҸҲжңүжүҖдёҚеҗҢгҖӮ
Depth-to-Image зҡ„зҺ©жі•еҫҲеӨҡпјҢеҸҜд»Ҙдә§з”ҹеҮәж— ж•°зңӢиө·жқҘдёҺеҺҹе§ӢеӣҫеғҸжҲӘ然дёҚеҗҢпјҢдҪҶеҸҲзӣёдјјзҡ„вҖңе…ӢйҡҶвҖқзүҲжң¬пјҡ
жӣҙж–°дҝ®еӨҚжү©ж•ЈжЁЎеһӢ
Stable Diffusion 2.0 иҝҳеҢ…жӢ¬дёҖдёӘж–°зҡ„ж–Үжң¬еј•еҜјдҝ®еӨҚ(text-guided inpainting)жЁЎеһӢпјҢиҝҷд№ҹжҳҜдёҠдёҖзүҲжң¬зҡ„ж”№иҝӣгҖӮе…·дҪ“иҜҙжқҘпјҢе°ұжҳҜеҰӮжһңжҲ‘们еҜ№з”ҹжҲҗдҪңе“Ғж•ҙдҪ“жҜ”иҫғж»Ўж„ҸпјҢдҪҶжҹҗдәӣйғЁеҲҶеҸҜиғҪеӯҳеңЁз‘•з–өпјҲжҜ”еҰӮиҜҙзңјзқӣпјүпјҢйӮЈжҲ‘们еҸҜд»ҘеҸӘй’ҲеҜ№з‘•з–өзҡ„йғЁеҲҶиҝӣиЎҢйҮҚж–°з”ҹжҲҗпјҢиҖҢе…¶е®ғйғЁеҲҶдҝқжҢҒдёҚеҸҳгҖӮжҲ–иҖ…еҸҚиҝҮжқҘдҪҝз”ЁпјҢдҝқжҢҒжҹҗдёӘйғЁеҲҶдёҚеҸҳпјҢеҜ№е…¶е®ғйғЁеҲҶйҮҚж–°з”ҹжҲҗпјҢиҝҷж ·еҸҜд»Ҙеҫ—еҲ°йқһеёёжңүи¶Јзҡ„з»“жһңгҖӮзҪ‘дёҠиҜёеӨҡжҒ¶жҗһдҪңе“Ғе°ұдҪҝз”ЁдәҶиҝҷз§ҚжҠҖе·§гҖӮ
е°Ҹз»“
дёҖиҲ¬жқҘиҜҙпјҢиҪҜ件еҸ‘еёғзҡ„дё»зүҲжң¬жӣҙж–°пјҢйҖҡеёёж„Ҹе‘ізқҖйҮҚеӨ§ж”№иҝӣпјҢеҰӮжһңиҰҒдҪ“йӘҢиҝҷдёҖеҠҹиғҪпјҢиҜ·и®ҝй—®е®ҳж–№еҸ‘еёғзүҲжң¬пјҡ
жҲ‘д№ӢеүҚдҪ“йӘҢзҡ„ејҖжәҗйЎ№зӣ® InvokeAIпјҢд№ҹејҖе§ӢиҝӣиЎҢдәҶ V2 жЁЎеһӢзҡ„ж”ҜжҢҒе·ҘдҪңпјҢзӣ®еүҚиҝҳдёҚеӨҹзЁіе®ҡпјҢ并没жңүеҗҲ并еҲ°дё»еҲҶж”ҜгҖӮ
еҗҺз»ӯжҲ‘е°ҶжҢҒз»ӯе…іжіЁ Stable Diffusion ејҖеҸ‘ж–№йқўзҡ„иҝӣеұ•пјҢеёҢжңӣиғҪдҪҝз”ЁжңҖж–°зҡ„е·Ҙе…·еҲӣдҪңеҮәжӣҙеҘҪзҡ„иүәжңҜдҪңе“ҒпјҢ敬иҜ·е…іжіЁгҖӮ




- 笔з”өе”®еҗҺеӨ§и§Јжһҗпјҹд»Ҙжғ жҷ®жҲҳ66дёәдҫӢ иҜҰз»ҶжӢҶи§Је”®еҗҺжңҚеҠЎ-еҪ“еүҚеҝ«и®Ҝ
- и®©дәәеҝғеҜ’пјҒзҲ·зҲ·10е…ғеҚ–з»ҷеӯҷеӯҗеӯҰеҢәжҲҝжғіиҰҒеӣһйҒӯжӢ’
- HTCеӣһеә”VRйғЁй—ЁдёҠеёӮдј й—»пјҡдёҚиҜ„и®әеёӮеңәж¶ҲжҒҜ жҳҺе№ҙдёҠеҚҠе№ҙе°ҶеҸ‘ж–°е“Ғ
- еӨ§еҰҲеҫ®дҝЎеӯҳ400дёҮжІЎи®ҫеҜҶз Ғ еҗҺз»ӯпјҡжүӢжңәе·ІжүҫеӣһпјҢй’ұиҝҳеңЁ
- Adobe з»ҳз”»еә”з”Ё Fresco зҺ°е·ІдёҠжһ¶еҫ®иҪҜеә”з”Ёе•Ҷеә—
- Bз«ҷжёҜиӮЎиӮЎд»·дёҠж¶Ёиҝ‘16% жҖ»еёӮеҖјзәҰиҫҫ610дәҝжёҜе…ғ
- 400д»ҘдёӢд№°2TBе°Ҷе®һзҺ° SSDеӣәжҖҒеҸҲйҷҚд»·дәҶ-еӨ©еӨ©зІҫйҖү
- divxжҳҜд»Җд№Ҳж јејҸпјҹdivxж јејҸиҪ¬жҚўзҡ„ж–№жі• еҸҜд»ҘиҝҗиЎҢDivxи§Јз ҒеҷЁиҝӣиЎҢи§ЈеҶі
- Acerз”өи„‘жҖҺд№Ҳз”ЁUзӣҳйҮҚиЈ…зі»з»ҹпјҹжңүйңҖиҰҒзҡ„е°ҸдјҷдјҙдёҚиҰҒй”ҷиҝҮжң¬ж•ҷзЁӢ
- з”өи„‘жЎҢ+з”өи„‘жӨ… еҘ—иЈ…жҗӯй…ҚдёҖеҘ—д»…200еҮәеӨҙ-еӨ©еӨ©еҝ«ж’ӯ
- Win8жҸҗзӨәвҖңWindowsе·Із»Ҹйҳ»жӯўжӯӨиҪҜ件еӣ дёәж— жі•йӘҢиҜҒеҸ‘иЎҢиҖ…вҖқ е»әи®®йҰ–е…Ҳе…ій—ӯзі»з»ҹйҳІзҒ«еўҷ
- еҝ«з”ЁиӢ№жһңеҠ©жүӢе®үиЈ…еӨұиҙҘи§ЈеҶіж•ҷзЁӢ дёӢиҪҪеҲ°зҡ„ж–Ү件жҚҹеқҸиҜҘжҖҺд№ҲеҠһ
- uзӣҳжҖҺд№Ҳи®ҫзҪ®зҰҒжӯўжӢ·иҙқеҶ…е®№пјҹ еҸҜдҪҝз”ЁвҖңеҸҜ移еҠЁеӯҳеӮЁи®ҝй—®вҖқиҝӣиЎҢзҰҒжӯў
- DedeCMSеҲӣе§Ӣдәәжһ—еӯҰе…Ҳз”ҹеӣ зҪ№жӮЈзҷҢз—ҮйҖқдё–
- IOS 10.0.0~10.0.2е®ҢзҫҺи¶ҠзӢұж•ҷзЁӢ иҜҘж•ҷзЁӢйҖӮз”Ёи®ҫеӨҮиҜҙжҳҺ
- дёҚиғҪи®ҝй—®windows installerжңҚеҠЎзҡ„и§ЈеҶіеҠһжі•жҳҜд»Җд№Ҳ иҝҷдёӘж“ҚдҪңжӯҘйӘӨж–№жі•еҝ«жқҘеӯҰд№
- жҖҺд№Ҳиҝӣе…Ҙи…ҫи®ҜQQиҒҠеӨ©е®Өпјҹ иҝҷдёӘж–№жі•дҪ еҸҜд»ҘеҸӮиҖғеӯҰд№
- Win7ж——иҲ°зүҲзҷ»еҪ•иҝӣзЁӢеҲқе§ӢеҢ–еӨұиҙҘеҰӮдҪ•и§ЈеҶіпјҹ е»әи®®йҖүжӢ©еҗҜеҠЁвҖңе®үе…ЁжЁЎејҸвҖқ
- DNFиҮӘеҠЁжӣҙж–°еӨұиҙҘжҖҺд№ҲеӨ„зҗҶпјҹtgpжӣҙж–°й”ҷиҜҜеҰӮдҪ•и§ЈеҶі
- 00еҗҺеҘіеӨ§еӯҰз”ҹеҒҡе®ҝиҲҚзҫҺз”ІжңҲе…ҘиҝҮдёҮ зҪ‘еҸӢзғӯи®®пјҡеӨ§еӯҰз”ҹеҲ°еә•иҜҘдёҚиҜҘе…јиҒҢпјҹ
- Win7зі»з»ҹжҖҺд№ҲеҲ©з”Ёи…ҫи®Ҝз”ө脑管家解еҶіи…ҫи®ҜQQж— жі•еҗҜеҠЁ пјҡеҸҜд»ҘеҚёиҪҪQQеҗҺйҮҚиЈ…
- qqзӯүзә§жңүд»Җд№Ҳз”Ёпјҹqqзӯүзә§жңүд»Җд№Ҳзү№жқғпјҹ зӯүзә§и¶Ҡй«ҳqqе® зү©еҠҹиғҪдјҡжӣҙеӨҡ жёёжҲҸжқғйҷҗд№ҹи¶ҠеӨҡ
- Win7зі»з»ҹжҸҗзӨәвҖңж— ж•Ҳзҡ„Windowsжҳ еғҸвҖқжҖҺд№ҲеҠһпјҹ еҝ«жқҘи§ӮзңӢжң¬ж•ҷзЁӢ
- еҗҢжӯҘеҠ©жүӢжҖҺж ·дҝ®еӨҚй—ӘйҖҖпјҹж•ҷдҪ еҰӮдҪ•йҮҚиЈ…жӯЈзүҲеә”з”Ё
- Vistaзі»з»ҹз”өи„‘еҚҮзә§е®үиЈ…Windows 7зі»з»ҹж•ҷзЁӢ еҰӮдҪ•еҖҹеҠ©зі»з»ҹе…үзӣҳиҝӣиЎҢеҚҮзә§
- гҖҠйӯ”е…Ҫдё–з•ҢгҖӢеӣҪжңҚжҳҺе№ҙеҒңиҝҗпјҡзӮ№еҚЎд»·ж јеӨ§ж¶Ё жёёжҲҸиө„дә§йҒӯз”©еҚ–
- дјҳй…·зңӢи§Ҷйў‘еҮәзҺ°з»ҝеұҸиҜҘеҰӮдҪ•и§ЈеҶіпјҹ пјҡеҸҜд»ҘеҸ–ж¶ҲеҗҜеҠЁзЎ¬д»¶еҠ йҖҹи®ҫзҪ®
- QQеҶңеңәжү“дёҚејҖжҖҺд№ҲеҠһпјҹе»әи®®зӣҙжҺҘжЈҖжҹҘFlashзүҲжң¬
- Win7ж——иҲ°зүҲеҰӮдҪ•еҝ«йҖҹе…ій—ӯ445з«ҜеҸЈпјҹ жү“ејҖжіЁеҶҢиЎЁеҗҺиҜҘзӮ№йҖүе“ӘдәӣеҖј
- е°Ҹзұіз¬”и®°жң¬ж·»еҠ ж–°зҡ„еӣәжҖҒзЎ¬зӣҳиҜҰз»Ҷж–№жі• е°Ҹзұіз¬”и®°жң¬ж·»еҠ зЎ¬зӣҳжіЁж„ҸдәӢйЎ№д»Ӣз»Қ
- ејҖжңәжҳҫзӨәBoot From CDдёҚиғҪиҝӣе…Ҙзі»з»ҹ еә”иҜҘеҰӮдҪ•и§ЈеҶі
- Win10 IEжөҸи§ҲеҷЁдё»йЎөдҝ®ж”№дёҚиҝҮжқҘжҖҺд№ҲеҠһпјҹиҝҷдёӨдёӘж–№жі•дҪ еҸҜд»ҘиҜ•дёҖиҜ•
- зҷҫеәҰж–Үеә“зҡ„еҶ…е®№жҖҺд№ҲеӨҚеҲ¶пјҹе…¶е®һж“ҚдҪңиө·жқҘйқһеёёз®ҖеҚ•
- Win7жҖҺд№Ҳиҝӣе…Ҙdosз•Ңйқў win7жЎҢйқўдёӢзҡ„DOSиҜҘеҰӮдҪ•ејҖеҗҜ
- жҲҝжәҗз®ЎзҗҶиҪҜ件жңүе“Әдәӣпјҹжўөи®ҜжҲҝеұӢз®ЎзҗҶзі»з»ҹжҖҺд№Ҳж ·еҘҪз”Ёеҗ—
- Win7з”өи„‘ж— жі•е…іжңәжҖҺд№ҲеҠһпјҹиҝҷдәӣи§ЈеҶіжӯҘйӘӨдҪ зҹҘйҒ“еҗ—
- Win10зі»з»ҹжҳҫеҚЎй©ұеҠЁе®үиЈ…еӨұиҙҘжҖҺд№ҲеҠһпјҹе»әи®®еҲ йҷӨд№ӢеүҚзҡ„жҳҫеҚЎй©ұеҠЁж–Ү件йҮҚж–°е®үиЈ…
- CDKEYжҳҜд»Җд№Ҳж„ҸжҖқпјҹпјҡе°ұжҳҜеёёиҜҙзҡ„еәҸеҲ—з Ғ жҲ–иҖ…иҜҙз§ҳй’Ҙ
- Win7иө„жәҗз®ЎзҗҶеҷЁиҖҒжҳҜйҮҚеҗҜеҰӮдҪ•и§ЈеҶіпјҹиҝҷж ·ж“ҚдҪңзҷҫеҲҶзҷҫиғҪи§ЈеҶіиө„жәҗз®ЎзҗҶеҷЁйҮҚеҗҜй—®йўҳ
- XPзі»з»ҹи®ҝй—®е…ұдә«жү“еҚ°жңәжҸҗзӨәжҢҮе®ҡзҡ„зҪ‘з»ңеҗҚдёҚеҶҚеҸҜз”Ёи§ЈеҶіжӯҘйӘӨ жҢҮе®ҡзҪ‘з»ңдёҚеҸҜз”Ёй—®йўҳжҖҺд№ҲеҠһпјҹ
- жҡ—жңҲе…”еӯҗд»Җд№ҲеұһжҖ§жңҖеҘҪ еҰӮдҪ•жүҚиғҪиҺ·еҫ—е® зү©жҡ—жңҲе…”пјҹ
- дёҮиғҪдә”笔иҫ“е…Ҙжі•еҰӮдҪ•жү“еҮәеҮ№еҮёдёӨеӯ—пјҹдә”笔编з ҒвҖңMMGDвҖқеҸҜжү“еҮәеҮ№еӯ—
- Winxpзі»з»ҹж— жі•и®ҝй—®е·ҘдҪңз»„жҖҺд№Ҳи§ЈеҶіпјҹеҲ жҺүGuestз”ЁжҲ·зҡ„ж“ҚдҪңеҸҜиЎҢеҗ—
- жҲҙе°”зҒөи¶Ҡ1464 жҲҙе°”зҒөи¶Ҡ1464зҡ„еҮ ж¬ҫеһӢеҸ·д»ҘеҸҠеҗ„иҮӘй…ҚзҪ®еҰӮдҪ•
- зҺӢдҪҚ继жүҝжі•жҳҜд»Җд№Ҳ WWJCе…ЁзҗғжүӢжңәи¶ҠзӢұејҖеҸ‘иҖ…еӨ§дјҡ科жҷ®
- зҙўе°је…°дәӯжҖҺд№ҲеҲ·жңә еҰӮдҪ•и®©жүӢжңәжҚўдёҠе…Ёж–°зі»з»ҹ
- зӨҫдјҡе…¬еҫ·зҡ„еҹәжң¬зү№еҫҒжҳҜд»Җд№Ҳ зӨҫдјҡе…¬еҫ·зҡ„дё»иҰҒеҶ…е®№и®Іи§Ј
- еҘҘе°је°”иә«й«ҳ жңүе…ідәҺеҘҘе°је°”иә«й«ҳж–№йқўзҡ„зҹҘиҜҶж•ҙзҗҶ
- зҷҫеәҰзҪ‘зӣҳе№ҙеҚЎжңҖдҪҺд»· зҷҫеәҰзҪ‘зӣҳе№ҙз»ҲзҰҸеҲ©йЎ»зҹҘ
- Win8жҖҺд№ҲйҮҚиЈ…зі»з»ҹWin7пјҹеҰӮжһңиҰҒжҒўеӨҚwin8зі»з»ҹиҜҘжҖҺд№ҲеҠһ
- QQзҡ®иӮӨжҖҺд№ҲжӣҙжҚўпјҹвҖңдёӘжҖ§иЈ…жү®вҖқеӣҫж ҮеңЁе“ӘйҮҢеҰӮдҪ•жү“ејҖ
- MIUI 14 жӣҙж–°ж—Ҙеҝ—еңЁжӯЈејҸеҸ‘еёғеүҚжі„йңІ
- еҪұйҹіе…Ҳй”ӢжҖҺд№ҲжҗңзүҮпјҹзЁӢеәҸе®үиЈ…еҢ…еә”иҜҘеңЁе“ӘйҮҢдёӢиҪҪ
- 2022е№ҙ12жңҲ05ж—Ҙ10ж—¶ж–°з–ҶзҹіжІіеӯҗз–«жғ…жңҖж–°еҮәе…Ҙж”ҝзӯ– ж–°з–ҶзҹіжІіеӯҗжңҖж–°з–«жғ…йҳІз–«жҺӘж–ҪдёҫжҺӘ
- Win7зі»з»ҹжҖҺд№Ҳеҝ«йҖҹз ҙи§Јз”өи„‘ејҖжңәеҜҶз ҒпјҹеҰӮдҪ•и°ғеҮәй«ҳзә§еҗҜеҠЁйҖүйЎ№
- иҜәеҹәдәҡйӣҶеӣўжңүйҷҗе…¬еҸёпјҡжҳҜе…ЁзҗғйўҶе…Ҳзҡ„移еҠЁйҖҡдҝЎдә§е“ҒеҲ¶йҖ е•Ҷ
- Epic收дёҚеҲ°йӘҢиҜҒз ҒжҖҺд№ҲеҠһ е»әи®®йҮҮз”ЁйқһQQйӮ®з®ұиҝӣиЎҢжіЁеҶҢ
- жҲҙ尔笔记жң¬еһӢеҸ·жҹҘиҜў дҪ зҹҘйҒ“жҲҙ尔笔记жң¬еһӢеҸ·жҖҺд№ҲеңЁз”өи„‘йҮҢжҹҘиҜўеҗ—
- еҲӣз»ҙе®ҳж–№зҪ‘ еҲӣз»ҙз”өи§Ҷе®ҳзҪ‘дёҺйӣҶеӣўе®ҳж–№зҪ‘з«ҷжҳҜд»Җд№Ҳ
- жқЁжғ еҰҚпјҡжӣҫж”№еҸҳзў§жЎӮеӣӯзҡ„з”ҹдә§жЁЎејҸ 并дҪҝе…¶жҲҗдёәдё–з•Ң500ејәдјҒдёҡ
- дёўеӨұlibeay32.dllдёҚиғҪдёҠзҪ‘е’ӢеҠһ жҖҺд№ҲеҒҡжүҚиғҪйҒҝе…ҚйҮҚиЈ…зі»з»ҹ
- зҲұжҷ®з”ҹr230жё…йӣ¶иҪҜ件жҖҺд№Ҳз”ЁпјҹдҪҝз”ЁеҗҺе°ұиғҪи®©зәўзҒҜеҒңжӯўй—ӘзғҒеҗ—
- еӯӨеІӣеҚұжңәйҖҡе…іж•ҷзЁӢжҳҜд»Җд№Ҳ дёәд»Җд№ҲеӯӨеІӣеӯҳжЎЈжІЎз”Ё еҸҜд»Ҙдҝ®ж”№й…ҚзҪ®ж–Ү件иҝҮе…іеҗ—
- Win10зғӯиЎҖж— иө–ејҖе§ӢжёёжҲҸй—ӘйҖҖжҖҺд№ҲеҠһпјҹеҸҜд»ҘдёӢиҪҪжёёжҲҸиҝҗиЎҢеә“и°ғж•ҙи®ҫзҪ®е…је®№жҖ§
- йј ж Үи“қзүҷе·Із»ҸиҝһжҺҘжҲҗеҠҹеҚҙжІЎжңүеҠһжі•дҪҝз”ЁжҖҺд№ҲеҠһпјҹи“қзүҷйј ж Үе·Із»ҸиҝһжҺҘдҪҶз”ЁдёҚдәҶи§ЈеҶіж–№жі•
- nokia8208пјҡдёәиҜәеҹәдәҡйҰ–ж¬ҫйҮҮз”Ёи§Ұж‘ёејҸжҢүй”®жүӢжңә жӢҚж‘„ж•Ҳжһңе°ҡеҸҜ
- е№»жғіжӣ№ж“Қдј ж”»з•ҘжӯЈејҸеҲ°жқҘ дёҖеҲҮй—®йўҳйғҪдёәеӨ§е®¶йҖҒдёҠи§Јзӯ”
- д»Ҡе№ҙTGAж—¶й•ҝе°Ҷжҳҫи‘—зј©зҹӯ еӨ§дҪңд№ҹеҸҳе°‘дәҶ-дё–з•Ңеҝ«иө„и®Ҝ
- 笔记жң¬з”өи„‘и“қзүҷеҠҹиғҪж— жі•ејҖеҗҜи§ЈеҶіеҠһжі• з”өи„‘и“қзүҷејҖдёҚдәҶжҖҺд№ҲеҠһпјҹ
- еҠһе©ҡзӨјеҗҺеҸ‘зҺ°еҘіеҸӢвҖңе·Іе©ҡвҖқ еҫ®дҝЎеҸ‘зҡ„520зәўеҢ…иғҪиҰҒеӣһжқҘеҗ—пјҹжі•йҷўеҲӨдәҶ
- еҚ•еҶ·з©әи°ғжҖҺд№Ҳж · еҚ•еҶ·з©әи°ғзү№зӮ№еҲҶжһҗ иҝҳеҸҜд»ҘеҒҡеҲ°еҮҖеҢ–з©әж°”дҪңз”Ё
- д№…зӯүдәҶпјҒгҖҠйҫҷи…ҫдё–зәӘ4гҖӢеҸ‘еёғе…Ёж–°йў„е‘Ҡпјҡи°ҒжҳҜжҒҗзӢјпјҹ-дё–з•Ңеҝ«ж’ӯжҠҘ
- ж–°д№°зҡ„з©әи°ғдёҚеҲ¶еҶ·жҳҜжҖҺд№ҲеӣһдәӢпјҹжҳҜеӣ дёәз©әи°ғзҡ„еҠҹзҺҮдёҚеӨҹд»ҘиҮҙдәҺдёҚеҲ¶еҶ·еҗ—
- з”өи„‘жҸҗзӨәwsappxеҶ…еӯҳеҚ з”ЁиҝҮй«ҳиҜҘжҖҺд№ҲеҠһпјҹWin10зі»з»ҹеҫ®иҪҜеә”з”Ёе•Ҷеә—ж— жі•жү“ејҖи§ЈеҶіж–№жі•
- з”·еӯҗе–Ӯе…»еұұдёӯзҷҪзӢҗ收еҲ°зҒөиҠқйҰҲиө иў«иҙЁз–‘ж‘ҶжӢҚ зҪ‘еҸӢпјҡеҸҜиғҪжҳҜиҗЁж‘©иҖ¶
- зҘһиҲҹеҚҒеӣӣеҸ·иҲӘеӨ©е‘ҳд№ҳз»„е№іе®үжҠөдә¬ 他们иҝ”еӣһең°йқўжҖ»е…ұеҲҶеҮ жӯҘпјҹ
- timplatform.exe timplatform.exeиҝӣзЁӢжҳҜд»Җд№Ҳ жҳҜеӨ–йғЁеә”з”ЁејҖеҸ‘жҺҘеҸЈз®ЎзҗҶзЁӢеәҸ
- ж—©пјҢVOGUEпҪңдёҺEstelleйҷҲз‘ңе…ұеҗҢејҖеҗҜ2022е№ҙжңҖеҗҺдёҖдёӘжңҲ
- 科йҫҷз©әи°ғжҳҫзӨәfcжҳҜд»Җд№Ҳж„ҸжҖқпјҹжҳҜFully clearзҡ„ж„ҸжҖқ жҸҗзӨәиҰҒжё…жҙҒж»ӨзҪ‘
- дҪіиғҪж‘„еғҸжңәеһӢеҸ·жҺЁиҚҗеҸҠзү№зӮ№д»Ӣз»Қ дҪіиғҪEOS C300еёӮеңәд»·жңүеӨҡй«ҳ
- еҫ•еҚЎжҺЁеҮәйҷҗйҮҸзүҲQ2ж•°з ҒзӣёжңәпјҢвҖңе№ҪзҒөвҖқй…ҚиүІзҲұеҗ—пјҹ-зғӯеӨҙжқЎ
- дјҠиҺұе…Ӣж–ҜеҶ°з®ұжҖҺд№Ҳж · дјҠиҺұе…Ӣж–ҜеҶ°з®ұзү№зӮ№д»Ӣз»Қ е·Ҙиүәе…Ҳиҝӣ дҝқйІңжҠҖжңҜзӘҒеҮә
- дё–з•ҢжқҜеёҰзҒ«еҪ©зҘЁз«ҷпјҡзӘҒеҮ»дёҖдёӘжңҲпјҢиөҡеӣһдёӨе№ҙжҲҝз§ҹ
- wifiж— зәҝзҪ‘з»ңж‘„еғҸжңәжҖҺд№Ҳе®үиЈ… дҪҝз”Ёе·Ҙе…·еҺҹж–ҷйңҖиҰҒе“Әдәӣ
- жҲ‘пјҢеңЁжӢјеӨҡеӨҡTemuеҚ–иҙ§пјҢдёҖеҚ•иөҡдёҖеқ—й’ұ
- жҖҺж ·и®ҫзҪ®жң¬ең°иҝһжҺҘip Windows 2000/XP IPең°еқҖеҸӮж•°и®ҫзҪ®иҜҙжҳҺ
- ж јеҠӣеҸҳйў‘з©әи°ғж•…йҡңд»Јз Ғжңүе“Әдәӣ E1е°Ҷд»ЈиЎЁеҶ·еҮқеҷЁеүҚжңүйҡңзўҚзү©зӯү
- еҫ·еӣҪиҺұеҚЎзӣёжңәеһӢеҸ·еҸҠжҠҘд»· еҫ•еҚЎV-LUXз„Ұи·қдёә25-400mm д»·еҖј8299е…ғ
- жӯӘжӯӘз§ҜеҲҶжңүд»Җд№Ҳз”ЁпјҹеҸҜд»Ҙз”ЁжқҘеҸӮеҠ жӯӘжӯӘе®ҳж–№жҙ»еҠЁзӯү
- иӢ№жһңжүӢжңәapple idеҜҶз ҒеҝҳдәҶжҖҺд№ҲеҠһ е·ІејҖеҗҜеҸҢйҮҚи®ӨиҜҒиҜҘеҰӮдҪ•жүҫеӣһ
- д»Җд№ҲжҳҜжҷәиғҪз”өи§Ҷ жҳҜжҢҮеғҸжҷәиғҪжүӢжңәе…·жңүе…ЁејҖж”ҫејҸе№іеҸ°зҡ„дә§е“Ғ
- дёӨж¬ҫй«ҳе“ҒиҙЁдёүжҳҹеҚ•еҸҚзӣёжңәжҺЁиҚҗпјҡдёүжҳҹsamsung NX200йҮҮз”ЁеӨҚеҸӨејҸи®ҫи®Ў
- й«ҳжё…з”өи§ҶеҲҶиҫЁзҺҮиҜҰи§Ј еҶіе®ҡй«ҳжё…з”өи§ҶзңҹдјӘзҡ„йҮҚиҰҒеӣ зҙ жҳҜд»Җд№Ҳ
- иҒ”жғіa20жҖҺд№Ҳж ·пјҹиҒ”жғіa20жҖ§иғҪиҜ„жөӢ дё»иҰҒдјҳеҠҝеңЁдәҺжӢҘжңүеңЁзәҝзӮ№ж’ӯеҠҹиғҪ
- й«ҳйҖҡйӘҒйҫҷ600жҖҺд№Ҳж · й«ҳйҖҡйӘҒйҫҷ600д»Ӣз»Қ иғҪе……еҲҶж»Ўи¶із”ЁжҲ·еҹәжң¬дҪ“йӘҢйңҖжұӮ
- дёүжҳҹi9500й…ҚзҪ®еҰӮдҪ•пјҹ16GB иҒ”йҖҡзүҲ3GжүӢжңәиҝҳжңүд»Җд№Ҳзү№зӮ№
- жңәжў°ејҸй”®зӣҳе“Әж¬ҫеҘҪгҖҖCherry G80-3800 MX2.0Cзҡ„дјҳзӮ№жҳҜд»Җд№Ҳ
- wlanзғӯзӮ№жҳҜд»Җд№Ҳж„ҸжҖқ ж„ҸдёәдҫҝжҗәејҸwlanзғӯзӮ№ еҸҜеҲҶдә«з»ҷе…¶д»–и®ҫеӨҮ
- uзӣҳеӨҡе°‘й’ұ uзӣҳжҠҘд»·еӨ§е…Ё йҮ‘еЈ«йЎҝDT100G3дёҺдёңиҠқ Osumi EX2жҖҺд№Ҳж ·
- иҒ”жғід№җpads1д»Ӣз»Қ зі»з»ҹиҝҗиЎҢйҖҹеәҰеҠ еҝ« еҖјеҫ—иҖғиҷ‘иҙӯд№°
ж–°й—»жҺ’иЎҢ
-
 жҜҸж—Ҙеҝ«ж’ӯпјҡPyCharm 2022.2 еҸ‘еёғдәҶпјҢж”ҜжҢҒжңҖж–° Python 3.11 е’Ң PyScript жЎҶжһ¶пјҒ
жҜҸж—Ҙеҝ«ж’ӯпјҡPyCharm 2022.2 еҸ‘еёғдәҶпјҢж”ҜжҢҒжңҖж–° Python 3.11 е’Ң PyScript жЎҶжһ¶пјҒ -
 е°Ҹзұіж–№еҗ‘зӣҳи„ұжүӢдё“еҲ©е…¬ејҖ иғҪеӨҹдёәиҫ…еҠ©й©ҫ驶系з»ҹжҸҗдҫӣдәҶеҮҶзЎ®зҡ„дҝЎжҒҜ
е°Ҹзұіж–№еҗ‘зӣҳи„ұжүӢдё“еҲ©е…¬ејҖ иғҪеӨҹдёәиҫ…еҠ©й©ҫ驶系з»ҹжҸҗдҫӣдәҶеҮҶзЎ®зҡ„дҝЎжҒҜ -
 186дёҮPanameraжҸ’ж··зүҲеҪ“иЎ—иө·зҒ«зғ§жҲҗеЈі дҝқж—¶жҚ·е®ўжңҚпјҡдёәеҒ¶еҸ‘жғ…еҶө
186дёҮPanameraжҸ’ж··зүҲеҪ“иЎ—иө·зҒ«зғ§жҲҗеЈі дҝқж—¶жҚ·е®ўжңҚпјҡдёәеҒ¶еҸ‘жғ…еҶө -
 еҗүеҲ©еҮ дҪ•е…Ёж–°иҪҰеһӢG6жӯЈејҸдә®зӣё ж–°иҪҰйҮҮз”ЁдәҶе°Ғй—ӯејҸеүҚж јж …
еҗүеҲ©еҮ дҪ•е…Ёж–°иҪҰеһӢG6жӯЈејҸдә®зӣё ж–°иҪҰйҮҮз”ЁдәҶе°Ғй—ӯејҸеүҚж јж … -
 й•ҝеҹҺжңәз”Ійҫҷе®һиҪҰжӯЈејҸжӣқе…ү ж–°иҪҰе°ҶжӢҘжңү7йў—800дёҮи¶…й«ҳжё…ж‘„еғҸеӨҙ
й•ҝеҹҺжңәз”Ійҫҷе®һиҪҰжӯЈејҸжӣқе…ү ж–°иҪҰе°ҶжӢҘжңү7йў—800дёҮи¶…й«ҳжё…ж‘„еғҸеӨҙ -
 е®Ҹе…үMINIEV GAMEBOYйҷҗйҮҸзүҲеҸ‘еёғ йғҪеёӮиҝҪйЈҺйҷҗйҮҸзүҲйҮҮз”ЁиҙҜз©ҝејҸеүҚи„ё
е®Ҹе…үMINIEV GAMEBOYйҷҗйҮҸзүҲеҸ‘еёғ йғҪеёӮиҝҪйЈҺйҷҗйҮҸзүҲйҮҮз”ЁиҙҜз©ҝејҸеүҚи„ё -
 з”өеҠЁsmartжҖ§иғҪзүҲе®ҳеӣҫжӣқе…ү ж–°иҪҰй…Қжңүе…Ёж¶Іжҷ¶д»ӘиЎЁзӣҳе’ҢжӮ¬жө®ејҸдёӯжҺ§еұҸ
з”өеҠЁsmartжҖ§иғҪзүҲе®ҳеӣҫжӣқе…ү ж–°иҪҰй…Қжңүе…Ёж¶Іжҷ¶д»ӘиЎЁзӣҳе’ҢжӮ¬жө®ејҸдёӯжҺ§еұҸ -
 зҗҶжғіе…Ёж–°дёӯеӨ§еһӢSUVзҺ°иә« ж–°иҪҰйҮҮз”ЁAR-HUDжҠ¬еӨҙжҳҫе’ҢдёӯжҺ§еұҸ幕жӣҝд»Ј
зҗҶжғіе…Ёж–°дёӯеӨ§еһӢSUVзҺ°иә« ж–°иҪҰйҮҮз”ЁAR-HUDжҠ¬еӨҙжҳҫе’ҢдёӯжҺ§еұҸ幕жӣҝд»Ј -
 зҲұ马仕еӣһеә”е®ҳзҪ‘еҲ йҷӨ16.5дёҮиҮӘиЎҢиҪҰпјҡеӣ дёәе®ғзҺ°еңЁе·Із»Ҹе”®з«ӯ
зҲұ马仕еӣһеә”е®ҳзҪ‘еҲ йҷӨ16.5дёҮиҮӘиЎҢиҪҰпјҡеӣ дёәе®ғзҺ°еңЁе·Із»Ҹе”®з«ӯ -
 е°ҸзұіMIX Fold 2еҚ•иҫ№д»…5.4mmеҺҡ й…ҚеӨҮж»ЎиЎҖLPDDR5+UFS3.1еӯҳеӮЁи§„ж ј
е°ҸзұіMIX Fold 2еҚ•иҫ№д»…5.4mmеҺҡ й…ҚеӨҮж»ЎиЎҖLPDDR5+UFS3.1еӯҳеӮЁи§„ж ј
зІҫеҪ©жҺЁиҚҗ
- 114дёҮдәәжғізңӢгҖҠйҳҝеҮЎиҫҫ2гҖӢ дёӯеӣҪзҘЁжҲҝеҸІжңүеҸҜиғҪиў«еҲ·ж–°еҗ—пјҹ
- еӨ§еҰҲеҫ®дҝЎеӯҳ400дёҮжүӢжңәдёўеӨұпјҡе®ҳж–№ж”Ҝ5жӢӣйҒҝе…ҚжҚҹеӨұ
- еҫ®дҝЎиҫҹи°Ј11жңҲжңӢеҸӢеңҲ10еӨ§и°ЈиЁҖпјҡз”өзғӯжҜҜгҖҒжҡ–е®қе®қжңүиҫҗе°„пјҹ
- з”Ёж—¶5е№ҙпјҒзү№ж–ҜжӢүдәӨд»ҳ第дёҖиҫҶз”өеҠЁеҚЎиҪҰ
- йў„е‘ҠзүҮжӣқе…ү жӣјиҫҫжҙӣдәәжҳҺе№ҙдёүжңҲж–°дёҖеӯЈж’ӯеҮә
- иҝӘж–Ҝе°ји¶…ејәAI дёҖй”®жј”е‘ҳе№ҙиҪ»жҲ–жҳҜиЎ°иҖҒ
- дәәдәәиғҪе»әжЁЎ EpicеҸ‘еёғ3Dе»әжЁЎжүӢжңәApp
- ZOL科жҠҖж—©йӨҗпјҡе°Ҹзұі13е”®д»·жӣқе…үпјҢжӣІйқўеұҸiPhone 14PMдә®зӣё
- з”өзғӯжҜҜгҖҒжҡ–е®қе®қжңүиҫҗе°„пјҹеҫ®дҝЎе…¬еёғ11жңҲжңӢеҸӢеңҲеҚҒеӨ§и°ЈиЁҖ
- иғҪз»ҷдҪ зңӢе“ӯдәҶ ж№ҳеҢ—VSеұұзҺӢ гҖҠзҒҢзҜ®й«ҳжүӢгҖӢеӨ§з”өеҪұд»Ҡж—ҘжӯЈејҸдёҠжҳ
и¶…еүҚж”ҫйҖҒ
- зҺ°еңЁз¬”и®°жң¬дё»жөҒй…ҚзҪ®жҳҜе“Әдәӣ зӢ¬з«Ӣ...
- еҚҺеӨ§еҹәеӣ еӣһеә”иў«е®һеҗҚдёҫжҠҘпјҡзі»жҚҸйҖ ...
- еҘҪиӮқпјҒеҚҡдё»иҝһзҺ©69е°Ҹж—¶жёёжҲҸз ҙеҗүе°ј...
- зәҪжӣјd118жҖҺд№Ҳж ·пјҹеӨ–и§Ӯи®ҫи®ЎйҮҮз”ЁеӨ§...
- Stable Diffusion 2.0 жқҘдәҶ-дё–з•ҢжҠҘйҒ“
- зҪ‘йЎөйЎөйқўи®ҫзҪ®жҖҺд№Ҳи®ҫзҪ® дё»йЎөиў«зҜЎ...
- 笔记жң¬жңүеҝ…иҰҒдҪҝз”Ёж•ЈзғӯеҷЁеҗ— еҰӮжһң...
- зҙўе°јзҲұз«ӢдҝЎs302cжүӢжңәжҖҺд№Ҳж · еҖј...
- uзӣҳжү“дёҚејҖдәҶжҖҺд№ҲеҠһ жү“дёҚејҖзҡ„жңҖ...
- йўҲжӨҺжҢүж‘©еҷЁе“ҒзүҢжҺ’иЎҢиҜҰжғ…д»Ӣз»Қ йўҲ...
- гҖҗжүӢж…ўж— гҖ‘й«ҳж•ҲеҠһе…¬е•Ҷз”ЁзҘһеҷЁи®ӨеҮҶ...
- дәҢе°әеӣӣзҡ„и…°еӣҙжҳҜеӨҡе°‘еҺҳзұі иҝҳжңүиЈӨ...
- з”өи„‘win7иҪҜ件管家жҺ’еҗҚ з®ҖжҙҒж— е№ҝ...
- iPhone7д»Җд№Ҳй…ҚзҪ®еҸӮж•°пјҹж Үй…Қжңүдё»...
- еҫ®иҪҜе·ІеҮҶеӨҮеҘҪйқўеҜ№FTCеҸҜиғҪжҸҗеҮәзҡ„иҜүи®ј
- дәҡйғҪеҠ ж№ҝеҷЁдёҚеҮәйӣҫеҺҹеӣ жҲ–и®ёдёәеҠ ...
- iphone5зҷҪиүІжҺүжјҶеҗ—пјҡеӣ жңәиә«дҪҝз”Ё...
- 3dmaxж•ҲжһңеӣҫеҲ¶дҪңжөҒзЁӢжқҘдәҶ е»әи®®...
- д»Җд№ҲзүҢеӯҗз©әи°ғеҘҪ зҫҺзҡ„жӢҘжңүдёӯеӣҪжңҖ...
- йҳҝд»Је°”ж№ҫзҡ„ж№ҝең° - з©әй—ҙз«ҷе®ҮиҲӘ...
- ж јеҠӣз©әи°ғе“ӘдёӘзі»еҲ—еҘҪ ж јеҠӣ KFR-...
- е®үеҚ“жүӢжңәеҶ…еӯҳеҚЎжё…зҗҶ иҝҷж ·е°ұеҸҜд»Ҙ...
- жүӢжңәrootеҗҺжҖҺд№ҲжҒўеӨҚ еҰӮдҪ•дҪҝз”ЁжүӢ...
- зәҝдёҠеј•жөҒжҺЁе№ҝеҰӮдҪ•еҒҡ жҖҺд№Ҳз”ЁеҺҹеҲӣ...
- ж¶Іжҷ¶з”өи§ҶжңәеҺ»е“ӘйҮҢжү№еҸ‘ иҙӯд№°ж—¶е»ә...
- btз§ҚеӯҗжҖҺд№ҲдёӢиҪҪ жҖҺд№ҲдёӢиҪҪзҡ„е…·дҪ“...
- з©әж°”еҺӢеҠӣдј ж„ҹеҷЁзҡ„е·ҘдҪңеҺҹзҗҶеҸҠжіЁж„Ҹ...
- йҘ®ж°ҙжңәжҖҺд№Ҳжё…жҙ— йҘ®ж°ҙжңәжё…жҙ—ж–№жі•...
- “жһңй“ҫдёҖе“Ҙ”з«Ӣи®ҜжҲҗжңҖеӨ§иӮЎдёңпјҹеҘҮ...
- зҷҫж–Ҝй”җзҫҪжҜӣзҗғжӢҚжҖҺд№Ҳж · дёҡдҪҷзҗғеҸӢ...
- ж јејҸеҢ–sdеҚЎзҡ„ж–№жі• ж јејҸеҢ–sdеҚЎжӯҘ...
- и°·жӯҢжөҸи§ҲеҷЁжҖҺд№Ҳи®ҫзҪ®дё»йЎө еҪ“жү“ејҖ...
- еҰӮдҪ•дҝ®ж”№ж”Ҝд»ҳе®қиҙҰжҲ·з»‘е®ҡзҡ„жүӢжңәеҸ·...
- йӣ·иӣҮжӣје·ҙзңјй•ңиӣҮжҖҺд№Ҳж · е…·жңү1600...
- ж·ҳе®қзҪ‘жү“дёҚејҖжҖҺд№ҲеҠһ жү“дёҚејҖзҡ„еҺҹ...
- зҰҒз”Ёи§ҰжҺ§жқҝжҖҺд№ҲеҒҡпјҹеҰӮжһңй…Қжңүи§Ұж‘ё...
- зЁҺжҺ§жңәдё“з”Ёжү“еҚ°жңәжҳҜд»Җд№Ҳ еҰӮдҪ•йҖү...
- еҰӮдҪ•еҢәеҲ«дҪҝз”Ё3з§ҚиҮӘеҠЁеҜ№з„Ұе’ҢжүӢеҠЁ...
- еҫ·з”ҹ收йҹіжңәе®ҳж–№ж——иҲ°еә—дёҺеҫ·з”ҹH-50...
- 360xboxжүӢжҹ„й©ұеҠЁжҖҺд№Ҳз”Ё пјҡйңҖиҰҒ...
- aз«ҷbз«ҷжҢҮзҡ„жҳҜд»Җд№Ҳж„ҸжҖқ е“ӘдёӘзҪ‘з«ҷ...
- backspaceжҳҜе“ӘдёӘй”® иҝҷдёӘжҢү键究...
- й«ҳйҖҹзӣёжңәжҳҜд»Җд№Ҳ жҳҜе·Ҙдёҡзӣёжңәзҡ„дёҖ...
- movж јејҸиҪ¬жҚў иҪ¬жҚўдёәMP4и§Ҷйў‘ж–Ү件...
- й—Әе®ўеҝ«и·‘2иғҢжҷҜйҹід№җжҳҜд»Җд№Ҳ жҳҜдёҖ...
- дёәд»Җд№Ҳи§Ҷйў‘дёҚиғҪж’ӯж”ҫ и§Ҷйў‘ж— жі•ж’ӯ...
- дјҒдёҡжҗңзҙўиҪҜ件е“ӘдёӘеҘҪ жҗңзҙўеј•ж“ҺдёҺ...
- qqйқ“еҸ·з”іиҜ·еҷЁ QQйқ“еҸ·е…Қиҙ№зүҲеҰӮдҪ•...
- еҘіеҢ…жү№еҸ‘иҙ§жәҗеңЁе“ӘйҮҢ еҢ…еҢ…жү№еҸ‘еёӮ...
- Ferragamo 2022еҒҮж—ҘзІҫйҖүзі»еҲ—

