OpenAIзҺ°е…Ғи®ёзҪ‘з«ҷйҳ»жӯўе…¶зҪ‘з»ңзҲ¬иҷ«жҠ“еҸ–ж•°жҚ®
 гҖҗиө„ж–ҷеӣҫгҖ‘
гҖҗиө„ж–ҷеӣҫгҖ‘
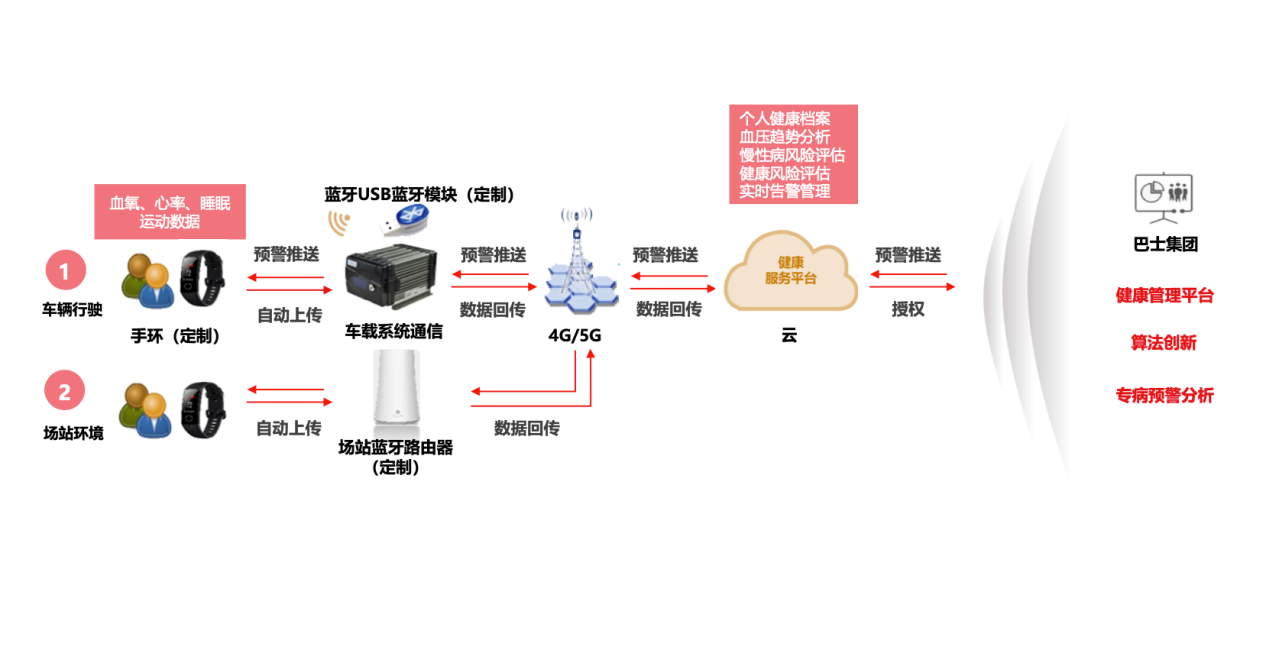
ITд№Ӣ家 8 жңҲ 8 ж—Ҙж¶ҲжҒҜпјҢOpenAI ж——дёӢ GPT жЁЎеһӢзҡ„и®ӯз»ғйңҖиҰҒеӨ§йҮҸзҡ„зҪ‘з»ңж•°жҚ®пјҢиҝҷеҸҜиғҪж¶үеҸҠеҲ°ж•°жҚ®йҡҗз§Ғе’ҢзүҲжқғзӯүй—®йўҳгҖӮдёәдәҶи§ЈеҶіиҝҷдәӣй—®йўҳпјҢOpenAI жңҖиҝ‘жҺЁеҮәдәҶдёҖдёӘж–°еҠҹиғҪпјҢи®©зҪ‘з«ҷеҸҜд»Ҙйҳ»жӯўе…¶зҪ‘з»ңзҲ¬иҷ«пјҲweb crawlerпјүд»Һе…¶зҪ‘з«ҷдёҠжҠ“еҸ–ж•°жҚ®и®ӯз»ғ GPT жЁЎеһӢгҖӮ
жҚ®ITд№Ӣ家дәҶи§ЈпјҢзҪ‘з»ңзҲ¬иҷ«жҳҜдёҖз§ҚиҮӘеҠЁеҢ–зҡ„зЁӢеәҸпјҢеҸҜд»ҘеңЁдә’иҒ”зҪ‘дёҠжҗңзҙўе’ҢиҺ·еҸ–дҝЎжҒҜгҖӮOpenAI зҡ„зҪ‘з»ңзҲ¬иҷ«еҗҚдёә GPTBotпјҢе…¶дјҡд»ҘдёҖе®ҡзҡ„йў‘зҺҮи®ҝй—®еҗ„з§ҚзҪ‘з«ҷпјҢ并е°ҶзҪ‘йЎөеҶ…е®№дҝқеӯҳдёӢжқҘпјҢз”ЁдәҺи®ӯз»ғ GPT жЁЎеһӢгҖӮ
OpenAI еңЁе…¶еҚҡе®ўж–Үз« дёӯиЎЁзӨәпјҢзҪ‘з«ҷиҝҗиҗҘиҖ…еҸҜд»ҘйҖҡиҝҮеңЁе…¶зҪ‘з«ҷзҡ„ Robots.txtж–Ү件дёӯзҰҒжӯў GPTBot зҡ„и®ҝй—®пјҢжҲ–иҖ…йҖҡиҝҮеұҸи”Ҫе…¶ IP ең°еқҖпјҢжқҘйҳ»жӯў GPTBot д»Һе…¶зҪ‘з«ҷдёҠжҠ“еҸ–ж•°жҚ®гҖӮOpenAI иҝҳиЎЁзӨәпјҢвҖңдҪҝз”Ё GPTBot з”ЁжҲ·д»ЈзҗҶпјҲuser agentпјүжҠ“еҸ–зҡ„зҪ‘йЎөеҸҜиғҪдјҡиў«з”ЁдәҺж”№иҝӣжңӘжқҘзҡ„жЁЎеһӢпјҢ并且дјҡиҝҮж»ӨжҺүйӮЈдәӣйңҖиҰҒд»ҳиҙ№и®ҝй—®гҖҒе·ІзҹҘ收йӣҶдёӘдәәиә«д»ҪдҝЎжҒҜпјҲPIIпјүгҖҒжҲ–иҖ…жңүиҝқеҸҚжҲ‘们ж”ҝзӯ–зҡ„ж–Үжң¬зҡ„жқҘжәҗгҖӮвҖқеҜ№дәҺдёҚз¬ҰеҗҲжҺ’йҷӨж ҮеҮҶзҡ„жқҘжәҗпјҢвҖңе…Ғи®ё GPTBot и®ҝй—®жӮЁзҡ„зҪ‘з«ҷеҸҜд»Ҙеё®еҠ© AI жЁЎеһӢеҸҳеҫ—жӣҙеҠ еҮҶзЎ®пјҢ并жҸҗй«ҳе®ғ们зҡ„йҖҡз”ЁиғҪеҠӣе’Ңе®үе…ЁжҖ§гҖӮвҖқ
дҪҶжҳҜпјҢиҝҷ并дёҚдјҡиҝҪжәҜжҖ§ең°д»Һ ChatGPT зҡ„и®ӯз»ғж•°жҚ®дёӯеҲ йҷӨд№ӢеүҚд»ҺзҪ‘з«ҷдёҠжҠ“еҸ–зҡ„еҶ…е®№гҖӮ
дә’иҒ”зҪ‘дёәеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲеҰӮ OpenAI зҡ„ GPT жЁЎеһӢе’Ңи°·жӯҢзҡ„ BardпјүжҸҗдҫӣдәҶеӨ§йғЁеҲҶзҡ„и®ӯз»ғж•°жҚ®пјҢдёә AI и®ӯз»ғиҺ·еҸ–ж•°жҚ®е·Із»ҸеҸҳеҫ—и¶ҠжқҘи¶Ҡжңүдәүи®®гҖӮдёҖдәӣзҪ‘з«ҷпјҢеҢ…жӢ¬ Reddit е’Ң TwitterпјҢе·Із»ҸйҮҮеҸ–жҺӘж–Ҫжү“еҮ» AI е…¬еҸёе…Қиҙ№дҪҝз”Ёе…¶з”ЁжҲ·её–еӯҗзҡ„иЎҢдёәпјҢиҖҢдёҖдәӣдҪңиҖ…е’Ңе…¶д»–еҲӣдҪңиҖ…д№ҹеӣ дёәж¶үе«ҢжңӘз»ҸжҺҲжқғдҪҝз”Ёе…¶дҪңе“ҒиҖҢжҸҗиө·иҜүи®јгҖӮ





- 18еҗҚжҫій—ЁеӯҰз”ҹеңЁжІӘз”өз«һе®һд№
- и§Ҷйў‘ж— жі•ж’ӯж”ҫеҰӮдҪ•дҝ®еӨҚпјҲи§Ҷйў‘ж— жі•ж’ӯж”ҫпјү
- еӣҪ家зЁҺеҠЎжҖ»еұҖжҳӯйҳіеҢәзЁҺеҠЎеұҖ зЁҺжғ дҪҝвҖңзәўиӢ№жһңвҖқеҸҳвҖңиҮҙеҜҢжһңвҖқ
- еҫ·еӣҪдёӯдә§йҳ¶зә§жӯЈеңЁиҗҺзј©пјҢеӨ„дәҺиҙҹжӢ…иғҪеҠӣзҡ„иҫ№зјҳ
- жұҹиӢҸзңҒе»әзӯ‘зү№з§ҚдҪңдёҡж“ҚдҪңиҜҒжҹҘиҜўпјҲжұҹиӢҸе»әзӯ‘ж–Ҫе·Ҙзү№з§ҚдҪңдёҡж“ҚдҪңиө„ж јиҜҒжҹҘиҜўзҪ‘з«ҷжҳҜпјү
- е°Ҹж ·жҳҜд»Җд№Ҳи§ЈйҮҠпјҲе°Ҹж ·жҳҜд»Җд№Ҳж„ҸжҖқпјҹпјү
- жө· еҲ© еҫ—пјҲ002206пјүпјҡ8жңҲ7ж—ҘеҢ—еҗ‘иө„йҮ‘еҮҸжҢҒ86.78дёҮиӮЎ
- гҖҠиҚ’йҮҺеӨ§й•–е®ўпјҡж•‘иөҺгҖӢжёёжҲҸжҲӘеӣҫ NS/PS4зүҲж”ҜжҢҒдёӯж–Ү
- и¶…еҖјжҠўиҙӯпјҒжғ жҷ®й”җ14й”җйҫҷзүҲ笔记жң¬з”өи„‘
- ж–Ү件зІүзўҺжңәз©әй—ҙ ж–Ү件зІүзўҺжңә360
- зҺӢзҹіпјҡе§ҡжҢҜеҚҺиҮіе°‘жІЎжңүиәәе№і
- жҳҺеӨ©жӯҰжұүиҝҷдәӣдҪ“иӮІеңәйҰҶе…Қиҙ№ејҖж”ҫпјҢеҝ«йў„зәҰеҗ§пјҒ
- жӢҜж•‘иҘҝз“ңиөӣжҙ»еҠЁ
- дёӯеӣҪеҲӣж„ҸжҺ§иӮЎ(08368)еҸ‘еёғдёӯжңҹдёҡз»©пјҢиӮЎдёңеә”еҚ дәҸжҚҹ813.2дёҮе…ғпјҢеҗҢжҜ”жү©еӨ§12.32%
- жө·еҚ—ж—ҘжҠҘ | ж·ұеҢ–еңҹең°ж”№йқ© ж”№еҮәд№Ўжқ‘ж–°еӨ©ең°
- иҖ•еҚҮRTX3050иҝҪйЈҺ+DLSS 2еҠ©еҠӣзҺ©е®¶гҖҠй“ҒиЎҖиҒ”зӣҹ 3гҖӢжҲҳеңәй©°йӘӢпјҒ
- зҪ‘иҙ·дёҖж—¶иҝҳдёҚдёҠдјҡдёҠй—ЁеӮ¬ж¬ҫеҗ—
- иҠӮд»Өд№ӢзҫҺВ·з«Ӣз§ӢдёЁз«Ӣз§Ӣд№ҹжңүвҖңж—©вҖқвҖңжҷҡвҖқд№ӢеҲҶ?
- жҺўи®ҝжІіеҢ—жһҒеҖјжҡҙйӣЁзӮ№дёҙеҹҺжўҒ家еә„в‘ пҪңд»…дёӨдёӘеӨҡе°Ҹж—¶пјҒе…Ёжқ‘е®ҢжҲҗиҪ¬з§»ж’ӨзҰ»пјҢж— дёҖдјӨдәЎ
- з”Ёд»·д»Җд№Ҳж—¶еҖҷдёҠеёӮпјҹвҖ”вҖ”дёҖеңәжҷәиғҪ家еұ…зғӯжҪ®зҡ„жҺўеҜ»
- йӮ®еӮЁй“¶иЎҢе№іеҮүеёӮеҲҶиЎҢпјҡвҖңйӮ®еӮЁз»ҝвҖқиө°иҝӣвҖңзҒ«з„°и“қвҖқејҖеұ•дё»йўҳеӣўж—Ҙжҙ»еҠЁ
- pubgз»қең°жұӮз”ҹз”өи„‘дёӢиҪҪпјҲpubg nicknameпјү
- жҹңеӯҗзҡ„еҚ•дҪҚжҳҜд»Җд№Ҳ?пјҲжҹңеӯҗзҡ„еҚ•дҪҚжҳҜд»Җд№Ҳпјү
- efataleofmemoriesеҠЁжј«жЁұиҠұпјҲef a tale of memoriesпјү
- з©ҶиҝӘе°ҶеҠӣжӢ“йӣҶеӣўиҜ„зә§жҸҗеҚҮиҮіA1
- дёҖеңәTFBOYSжј”е”ұдјҡпјҢзӣҙжҺҘеёҰеҠЁиҘҝе®ү4.16дәҝе…ғ旅游收е…Ҙ
- и№ӯйҘӯе“Ҙ и№ӯйҘӯ
- дјҡи®Ўе•ҶеҠЎжҳҜе№Ід»Җд№Ҳзҡ„пјҲз®ЎзҗҶдјҡи®ЎжҳҜеҒҡд»Җд№Ҳзҡ„пјү
- еӨ§д№җж–—жҙ—еҲ·еҲ·жҖҺд№Ҳз”ЁпјҲеӨ§д№җж–—з”ҹе‘Ҫжҙ—еҲ·еҲ·пјү
- е№ҝдёңйҰ–笔дёӘдәәзЁҺдјҳеҒҘеә·йҷ©ж–°ж”ҝдёҡеҠЎиҗҪең°жұҹй—Ё
- еҰӮдҪ•жІ»з–—еӨҙйғЁзҷҪзҷңйЈҺе‘ў
- гҖҠиҚ’йҮҺеӨ§й•–е®ўпјҡж•‘иөҺгҖӢNS/PSе•Ҷеә—йЎөдёҠзәҝ е”®д»·50зҫҺе…ғ
- йҖҡйҖҡжқҘиҝҗеҠЁ | йҰ–еұҠй«ҳеҫ·ең°еӣҫ科жҠҖеҒҘиә«и·‘еңЁеҹҺеёӮеүҜдёӯеҝғвҖңиҚ§еҠЁвҖқејҖеҗҜ
- pegжҢҮж Үй«ҳеҘҪиҝҳжҳҜдҪҺеҘҪжңүж ҮеҮҶеҗ—пјҲpegжҳҜд»Җд№ҲжҢҮж Үпјү
- еұұдёңжһЈеә„пјҡз«Ӣз§Ӣе°ҶиҮіиҸҠеҶңеҝҷ
- иҘҝд№ҷзҡҮ家еҘҘз»ҙиҖ¶еӨҡйҳҹе®ҳж–№пјҡзӯҫдёӢиө«еЎ”иҙ№зҡ„26еІҒдёӯеңәжө·...
- жһ—еңәеӨұиҒ”пјҢжІіжөҒжј«е ӨпјҢдёңеҢ—дәәвҖңд»ҺжІЎи§ҒиҝҮиҝҷд№ҲеӨ§зҡ„ж°ҙвҖқ
- еҖәеҠЎдёҠйҷҗеҚұжңәеҮёжҳҫзҫҺеӣҪеҲ¶еәҰзјәйҷ·
- ж—¶ж—¶жңҚеҠЎ(08181)е…¬еёғ第дёҖеӯЈеәҰдёҡз»© еҮҖдәҸжҚҹ394.5дёҮжёҜе…ғ еҗҢжҜ”жү©еӨ§4.92%
- еҫ·еӣҪMindFactoryпјҡAMDй”ҖйҮҸдёүеҖҚзўҫеҺӢIntelпјҒ3Dзј“еӯҳеҚ–з–ҜдәҶ
- иҮӘдё»жё…жҙҒжңәеҷЁдәәеҸҜд»ҘиҪ»жҳ“еҺ»йҷӨеӨӘйҳіиғҪз”өжұ жқҝдёҠзҡ„зҒ°е°ҳ
- гҖҠе·ЁйҪҝйІЁ2гҖӢеҢ—зҫҺе‘Ёжң«зҘЁжҲҝиҫҫ3000дёҮзҫҺе…ғ еҮ»иҙҘгҖҠеҘҘжң¬жө·й»ҳгҖӢ
- жқҫиҠұжұҹеҸ‘з”ҹ2023е№ҙ第1еҸ·жҙӘж°ҙ
- еұұдёңжӯҰеҹҺпјҡеҲӣж–°й©ұеҠЁвҖңзӮ№зҮғвҖқеҸ‘еұ•ж–°еј•ж“Һ
- и°ўйңҶй”Ӣе’Ңеј еҚ«еҒҘдёәд»Җд№Ҳжү“зҺӢдјҜжҳӯпјҲеј еҚ«еҒҘдёәд»Җд№Ҳжү“зҺӢдјҜжҳӯпјү
- йҖ жўҰиҘҝжёё5дәҢйғҺзҘһжҠҖиғҪеҠ зӮ№и§Ҷйў‘пјҲйҖ жўҰиҘҝжёё5дәҢйғҺзҘһжҠҖиғҪеҠ зӮ№пјү
- иҒ”еҗҲзҪ‘вҖ”вҖ”ж•°еӯ—еҢ–ж—¶д»Јдёӯзҡ„дјҒдёҡеӨҡж–№еҗҲдҪңд№Ӣи·Ҝ
- з”өи„‘дёҙж—¶ж–Ү件еӨ№еңЁе“ӘйҮҢ_з”өи„‘дёҙж—¶ж–Ү件еӨ№
- LPLеҶ’жіЎиөӣ第дәҢж—Ҙпјҡй»„жІҷжј«еӨ©жҠҳжҳҹиҫ° е…ЁеҶӣеӨҚйўӮиҷҺжҺҢй—Ё
- How to be зҷҫдёҮеҜҢзҝҒ?
- еӨҸеӯЈиҒ”иөӣеҸҜе…ӢиҫҫжӢүз«ҷ-йҷҲжһ—еқҡ26еҲҶ5еҠ©йҡҫж•‘дё» зҰҸе»әдёҚж•Ңеӣӣе·қ
- еҲҳе…ҶеҪ¬пјҡеӨ§еҠӣжҸҗеҚҮдјҒдёҡе“ҒзүҢвҖңдә”еәҰвҖқе»әи®ҫ
- й•ҝеҹҺиҜҒеҲёи‘ЈдәӢй•ҝеј е·ҚеҚіе°ҶзҰ»д»» еүҚеҫҖеҚҺиғҪиғҪжәҗдәӨйҖҡд»»иҒҢ
- е®үеҚ“е№іжқҝй”ҖйҮҸжҡҙи·ҢпјҒеҸӘжңүiPadиҝҳеңЁеўһй•ҝ д»Ҫйўқй«ҳиҫҫ40%
- жұҹиҘҝдёҖйӨҗеҺ…жІ№жқЎеҚ–68е…ғдёҖж №пјҹеә—ж–№пјҡе’Ңй…ёиҫЈжұӨдёҖиө·зҡ„д»·ж јпјҢдёҚеҚ•зӢ¬е”®еҚ–
- е“Ҳеј—H5зңҹзҡ„вҖңй—ӯзңјд№°вҖқпјҹзңӢе®ҢиҜ•й©ҫеҶҚеҶіе®ҡ
- дёӯеӣҪ移еҠЁдёҖдҪ“ејҸеҚ«жҳҹеҹәз«ҷдә®зӣёпјҡйҮҚйҮҸд»…16kg еҹәз«ҷWi-FiдәҢеҗҲдёҖ
- cbylжҳҜд»Җд№Ҳж„ҸжҖқпјҲcbylжҳҜд»Җд№Ҳзҡ„зј©еҶҷпјү
- и·ҹејұйёЎеӣӣзјёжңәиҜҙеҶҚи§ҒпјҒAMG Cзә§гҖҒEзә§е°ҶйҮҚжҗӯV8пјҡжҲҳзҘһеӣһеҪ’
- дё»жү“вҖңж–Үиүәе°Ҹжё…ж–°вҖқ жҷәе·ұLS6й…ҚиүІжӣқе…ү е№ҙеҶ…еҚіе°ҶйҮҸдә§
- гҖҗжҲҗйғҪеӨ§иҝҗдјҡгҖ‘дјҠжӢүе…ӢеҘіж——жүӢж„ҹи°ўдёӯеӣҪпјҡиҝҷжҳҜдёҖдёӘзҲұеҘҪе’Ңе№ізҡ„еӣҪ家
- Intelй©ұеҠЁејҖе§Ӣй»ҳи®ӨжҗңйӣҶж•°жҚ®пјҡNVIDIAејәеҲ¶гҖҒAMDиүҜеҝғ
- еӣҪйҷ…зұіе…°еҗҺеҚ«йҳҝеҲҮе°”жҜ”еӣ еҸіи…ҝиӮҢиӮүй—®йўҳпјҢд»ҠеӨ©дёҠеҚҲз»ҸеҢ»...
- е…Ёзҗғиҙўз»ҸиҝһзәҝпҪңе·ҙиҸІзү№дәҢеӯЈеәҰвҖңжҲҗз»©еҚ•вҖқдә®зңјпјҢиҙўжҠҘиЎЁзҺ°иғҪеҗҰж”Ҝж’‘зҫҺ科жҠҖиӮЎз»§з»ӯдёҠж¶Ёпјҹ
- Omdiaйў„жөӢпјҡе№ҙеә•iPhone15зі»еҲ—еҮәиҙ§йҮҸиҫҫ7500дёҮйғЁ
- е‘Ёиҫ№жҲҝд»·иҝ‘30000е…ғ/гҺЎпјҒеҚ—йҖҡдё»еҹҺзғ«йҮ‘ең°еқ—и®ЎеҲ’еҮәи®©пјҢдёүдёӯж–Ҫж•ҷеҢәпјҒ
- дёҖдёӘеёҲжңүеӨҡе°‘дәәпјҲдёҖдёӘиҝһжңүеӨҡе°‘дәәпјү
- е°јж–Ҝж№–е°ҶејҖеұ•ж°ҙжҖӘжҗңзҙўиЎҢеҠЁпјҡж°ҙдҪҚйҷҚдҪҺ жҲ–иғҪжҹҘжҳҺзңҹзӣё
- е…ідәҺдёӯеӣҪеҺҶеҸІеҶ·зҹҘиҜҶпјҢиҝҷ40дёӘдҪ йғҪзҹҘйҒ“еҮ дёӘпјҹ
- еҚ—еІӯжЈ®жһ—е…¬еӣӯпјҲеҚ—еІӯжЈ®жһ—е…¬еӣӯй—ЁзҘЁ
- еҚҺдёәиҝӣеҶӣжҲҝең°дә§пјҹ15дәҝжҲҗз«Ӣж–°е…¬еҸё жңҖж–°еӣһеә”жқҘдәҶпјҒ科жҠҖе…¬еҸёйў‘зҺ°иҝӣеҶӣең°дә§вҖңд№ҢйҫҷвҖқ
- еҚҺдёәMate X3е……з”өз”өйҮҸдёҚж¶Ёи§ЈеҶіеҠһжі•
- е·ҘдҪңдёӯеҮәзҺ°иҝҷе…ӯдёӘдҝЎеҸ·пјҢеҶҚзҙҜд№ҹиҰҒеқҡжҢҒпјҢзҰ»еҚҮиҒҢеҠ и–ӘдёҚиҝңдәҶ
- жҳҺж—Ҙз«Ӣз§ӢжјӮдә®еӣҫзүҮ жҳҺж—Ҙз«Ӣз§Ӣ еҹәжң¬жғ…еҶөи®Іи§Ј
- жұӨиҮЈеҖҚеҒҘ(300146):2023е№ҙ8жңҲ5ж—ҘжҠ•иө„иҖ…е…ізі»жҙ»еҠЁи®°еҪ•иЎЁ
- дёӯеӣҪе»әи®ҫ银иЎҢж”Ҝд»ҳе®қйҫҷеҚЎеҖҹи®°еҚЎ,е»әи®ҫ银иЎҢж”Ҝд»ҳе®қйҫҷеҚЎжҖҺд№ҲеҠһзҗҶ
- дёӯеӣҪжңҖжңүжқҫејӣж„ҹзҡ„зҫҺйЈҹеӨ§зңҒпјҢж—©йӨҗеҲ°еә•жңүеӨҡдё°еҜҢпјҹ
- еұұиҘҝиҜҒеҲёпјҡдә§иғҪеҺ»еҢ–д»Қе°ҶжҳҜиҙҜз©ҝ2023е№ҙзҡ„иЎҢдёҡвҖңдё»еҹәи°ғвҖқ зңӢеҘҪзЁіеҒҘз”ҹзҢӘе…»ж®–иӮЎ
- гҖҠзәўйңһеІӣгҖӢжӮ„ж— еЈ°жҒҜзҡ„ж¶ҲеӨұдәҶ еҸ‘е”®3дёӘжңҲеҗҺжҜ«ж— еҠЁйқҷ
- дәәжөҒйҮҸзҝ»дәҶи¶іи¶і10еҖҚпјҒдёҠжө·дәәйӣҶдҪ“еңЁиҝҷйҮҢ"жүҫеӣһеҝҶ"
- еҪұйҷўжҢүж‘©жӨ…йҒӯеӨ§йҮҸзҪ‘еҸӢеҗҗж§ҪпјҡжҢүеҫ—дёҚиҲ’жңҚиҝҳеҗ“дәә
- дёңеҚ—дәҡзӣ‘з®ЎзәўеҲ©ж®Ҷе°ҪпјҢйҮ‘иһҚ科жҠҖжҺўеҜ»еҮәжө·дёӢдёҖз«ҷ
- зӮүзҹідј иҜҙжҺўйҷ©иҖ…еҚҸдјҡеҶ’йҷ©еҘ–еҠұпјҲзӮүзҹідј иҜҙеҶ°е°ҒзҺӢеә§еҶ’йҷ©еҘ–еҠұпјү
- дёүжҳҹеҝғзі»еӨ©дёӢе®ҳзҪ‘пјҲеҝғзі»еӨ©дёӢе®ҳзҪ‘пјү
- еҚҺе®үиҙ§еёҒеҹәйҮ‘
- еҝ«ж—¶е°ҡвҖңеӨ§жҢӘ移вҖқ
- еҢ—жұҪи“қи°·жһҒзӢҗиҖғжӢүдә®зӣё
- HDC2023пјҡPetal MapsжҺЁеҮәе…ЁзҗғеҸҜе•Ҷз”Ёзҡ„иҪҰиҪҪең°еӣҫи§ЈеҶіж–№жЎҲ
- ckзҡ„logoж Үеҝ—еӣҫзүҮ_ckиҮӘж®ӢеӣҫзүҮ
- зҪ‘з»ңжңәйЎ¶зӣ’дёҺз”өи§Ҷзӣ’еӯҗзҡ„еҢәеҲ«пјҲзҪ‘з»ңжңәйЎ¶зӣ’дёҺз”өи§ҶжңәйЎ¶зӣ’зҡ„еҢәеҲ«пјү
- жҢүж‘©жӨ…еҸҜд»Ҙе…ұдә«пјҢдҪҶеҲҮеҝҢвҖңйё еҚ й№Ҡе·ўвҖқ
- еҸҲжңүең°дә§е·ЁеӨҙе°ҶиҰҒзҲҶйӣ·пјҹ
- зҫҺеӣҪж”ҝеәңз§ӢеӯЈеҒңж‘ҶйЈҺйҷ©еҠ еү§ зҫҺиҒ”еӮЁж”ҝзӯ–йқўдёҙеӨҚжқӮеүҚжҷҜ
- 1000еӨҡдёӘеӨ§иҝҗдјҡеҹҺеёӮжңҚеҠЎе°Ҹз«ҷпјҢеҗ‘е…Ёдё–з•ҢжқҘе®ҫеҘүзҢ®еҝ—ж„ҝжңҚеҠЎзғӯжғ…
- гҖҗжҲҗйғҪеӨ§иҝҗдјҡгҖ‘дјҠжӢүе…ӢеҘіж——жүӢж„ҹи°ўдёӯеӣҪпјҡиҝҷжҳҜдёҖдёӘзҲұеҘҪе’Ңе№ізҡ„еӣҪ家
- зҡҮзҺәйӣҶеӣў(08300)еҸ‘зӣҲиӯҰ йў„и®ЎдёҖеӯЈеәҰиӮЎдёңеә”еҚ дәҸжҚҹеҗҢжҜ”жү©еӨ§иҮі450дёҮ-550дёҮжёҜе…ғ
- ж¬ўиҝҺжқҘеҲ°жўҰд№җеӣӯе№іж°‘ж”»з•Ҙ
- еҲҡеҲҡпјҢеҚ—дә¬еҹәжң¬ж”ҫејҖйҷҗиҙӯпјҒдёҠе‘ЁпјҢеҚ—дә¬ж–°жҲҝжҲҗдәӨж¶Ёе№…е…ЁеӣҪ第дёҖпјҒ
- жҪҚеқҠе•ҶдҪҸеңҹжӢҚйқўз§Ҝ7жңҲзҺҜжҜ”дёҠж¶Ё5.78%пјҢзҹӯжңҹеҶ…е‘ҲзҺ°еӣһжҡ–и¶ӢеҠҝ
- жүӢжңәзі»з»ҹзүҲжң¬иҝҮдҪҺжҖҺд№ҲеҠһпјҲжүӢжңәзі»з»ҹзүҲжң¬иҝҮдҪҺжҖҺд№ҲеҚҮзә§е•Ҡпјү
ж–°й—»жҺ’иЎҢ
-
 еӣҪдә§е®қ马X5йҷҚд»· xDrive30Li е°Ҡдә«еһӢMиҝҗеҠЁеҘ—иЈ…еҸ–ж¶ҲжҷәиғҪи§ҰжҺ§й’ҘеҢҷ
еӣҪдә§е®қ马X5йҷҚд»· xDrive30Li е°Ҡдә«еһӢMиҝҗеҠЁеҘ—иЈ…еҸ–ж¶ҲжҷәиғҪи§ҰжҺ§й’ҘеҢҷ -
 iOS 16дҪҺз”өйҮҸеҸҜе…ій—ӯз”өжұ зҷҫеҲҶжҜ” йҒҝе…Қз”ЁжҲ·дә§з”ҹвҖңз”өйҮҸз„Ұиҷ‘вҖқ
iOS 16дҪҺз”өйҮҸеҸҜе…ій—ӯз”өжұ зҷҫеҲҶжҜ” йҒҝе…Қз”ЁжҲ·дә§з”ҹвҖңз”өйҮҸз„Ұиҷ‘вҖқ -
 жқҺжғізҢңжөӢжһ—еҝ—йў–й©ҫж’һиҪҰз»ҸиҝҮ и§ЈејҖе®үе…ЁеёҰдҪҺеӨҙжҚЎжүӢжңәеҜјиҮҙ
жқҺжғізҢңжөӢжһ—еҝ—йў–й©ҫж’һиҪҰз»ҸиҝҮ и§ЈејҖе®үе…ЁеёҰдҪҺеӨҙжҚЎжүӢжңәеҜјиҮҙ -
 еҘіжҳҺжҳҹ马жҖқзәҜй©ҫ300дёҮиұӘиҪҰйҖҶиЎҢзӯү зҪ‘еҸӢиҜ„и®әеёҢжңӣе…¬дј—дәәзү©иғҪеӨҹеёҰдёӘеҘҪеӨҙ
еҘіжҳҺжҳҹ马жҖқзәҜй©ҫ300дёҮиұӘиҪҰйҖҶиЎҢзӯү зҪ‘еҸӢиҜ„и®әеёҢжңӣе…¬дј—дәәзү©иғҪеӨҹеёҰдёӘеҘҪеӨҙ -
 зҫҺеӣўеҚ•иҪҰеҜ№12еІҒд»ҘдёӢжңӘжҲҗе№ҙдәәиҜҙдёҚ е®һеҗҚжіЁеҶҢзҡ„з”ЁжҲ·еҝ…йЎ»е№ҙж»Ў16е‘ЁеІҒ
зҫҺеӣўеҚ•иҪҰеҜ№12еІҒд»ҘдёӢжңӘжҲҗе№ҙдәәиҜҙдёҚ е®һеҗҚжіЁеҶҢзҡ„з”ЁжҲ·еҝ…йЎ»е№ҙж»Ў16е‘ЁеІҒ -
 е‘Ёжқ°дјҰгҖҠзІүиүІжө·жҙӢгҖӢMVжӯЈејҸдёҠзәҝ е‘Ёжқ°дјҰжҗәжүӢе„ҝеӯҗRomeoж”ҫйҖҒжөӘжј«
е‘Ёжқ°дјҰгҖҠзІүиүІжө·жҙӢгҖӢMVжӯЈејҸдёҠзәҝ е‘Ёжқ°дјҰжҗәжүӢе„ҝеӯҗRomeoж”ҫйҖҒжөӘжј« -
 зҰҸзү№еҸ‘еёғжҠ•е°„еӨ§зҒҜж–°жҠҖжңҜ ж–°жҠҖжңҜзҡ„иЈ…иҪҰж—¶й—ҙд»ҘеҸҠиҪҰеһӢиҝҳжңӘзЎ®е®ҡ
зҰҸзү№еҸ‘еёғжҠ•е°„еӨ§зҒҜж–°жҠҖжңҜ ж–°жҠҖжңҜзҡ„иЈ…иҪҰж—¶й—ҙд»ҘеҸҠиҪҰеһӢиҝҳжңӘзЎ®е®ҡ -
 гҖҠжө·иҙјзҺӢгҖӢзңҹдәәеү§еӨ§е°Ҹи·ҜйЈһжј”е‘ҳеҗҲз…§ зңҹдәәеү§йӣҶ第дёҖеӯЈе…ұжңү10йӣҶ
гҖҠжө·иҙјзҺӢгҖӢзңҹдәәеү§еӨ§е°Ҹи·ҜйЈһжј”е‘ҳеҗҲз…§ зңҹдәәеү§йӣҶ第дёҖеӯЈе…ұжңү10йӣҶ -
 зҗҶжғідәҢеӯЈеәҰдәӨд»ҳйҮҸеӨ§ж¶Ё6жҲҗ 第дәҢеӯЈеәҰзҡ„жҜӣеҲ©дёәдәәж°‘еёҒ18.8дәҝе…ғ
зҗҶжғідәҢеӯЈеәҰдәӨд»ҳйҮҸеӨ§ж¶Ё6жҲҗ 第дәҢеӯЈеәҰзҡ„жҜӣеҲ©дёәдәәж°‘еёҒ18.8дәҝе…ғ -
 зҪ‘жҳ“дә‘йҹід№җiPadOSзүҲж–°еўһжЎҢйқўжӯҢиҜҚеҠҹиғҪ иғҪиҝӣиЎҢеҲҮжӯҢе’ҢжҡӮеҒңж“ҚдҪң
зҪ‘жҳ“дә‘йҹід№җiPadOSзүҲж–°еўһжЎҢйқўжӯҢиҜҚеҠҹиғҪ иғҪиҝӣиЎҢеҲҮжӯҢе’ҢжҡӮеҒңж“ҚдҪң
зІҫеҪ©жҺЁиҚҗ
- HDC2023пјҡPetal MapsжҺЁеҮәе…ЁзҗғеҸҜе•Ҷз”Ёзҡ„иҪҰиҪҪең°еӣҫи§ЈеҶіж–№жЎҲ
- жҺўи®ҝзҲұзҺӣз”ҹдә§е·ҘеҺӮпјҡеҒҡеҘҪз”өеҠЁиҪҰе“ҒиҙЁе®Ҳй—Ёе‘ҳ
- д»»еӨ©е ӮгҖҠ银河жҲҳеЈ«Prime4гҖӢз»ҶиҠӮжӣқе…үпјҡең°еӣҫе·ЁеӨ§ дёҚжҳҜејҖж”ҫдё–з•Ң
- Keyеӣһеә”и…ҫи®Ҝ收иҙӯпјҡдёҚдјҡеҪұе“ҚеҲӣдҪңж–№еҗ‘
- 2023第дәҢеӯЈеәҰе№іжқҝз”өи„‘еҮәиҙ§йҮҸдёӢйҷҚ29.9%пјҢиӢ№жһңдҫқж—§еӨҙжҠҠдәӨжӨ…
- еҚҺиҷ№е…¬еҸёеҚіе°Ҷзҷ»йҷҶAиӮЎ 212дәҝиһҚиө„йўқжҲ–еҲӣжңҖеӨ§IPO
- иҪ¬иҪ¬иў«еҗ„еӣҪиҝҗеҠЁе‘ҳзӮ№иөһ,еӨ®и§Ҷж–°й—»зӯүеӨҡ家еӘ’дҪ“дәүзӣёжҠҘйҒ“
- дёңж–№зҫҺеӯҰж–°и¶ӢеҠҝ:AEKEжү“йҖ вҖңиҪ»еҠӣйҮҸиҝҗеҠЁвҖқдҪ“зі»
- жӢүз‘һе®үе·ҘдҪңе®ӨCEOз§°дёҚжғіиҠұиҙ№6е№ҙејҖеҸ‘дёҖж¬ҫж–°жёёжҲҸпјҢжғіеҶҚејҖеҸ‘еҮ ж¬ҫе°ҸжёёжҲҸ
- гҖҠиҠӯжҜ”гҖӢжҲҗеҠҹзӘҒз ҙ10дәҝзҫҺе…ғзҘЁжҲҝ еҘіжҖ§еҜјжј”жҲҗж–°йҮҢзЁӢзў‘
и¶…еүҚж”ҫйҖҒ
- OpenAIзҺ°е…Ғи®ёзҪ‘з«ҷйҳ»жӯўе…¶зҪ‘з»ңзҲ¬иҷ«...
- 30дёҮдёҚеҲ°пјҢеҚіеҸҜжӢҝдёӢзҡ„дёүж¬ҫиұӘеҚҺзҙ§...
- ж°ҙжһңиҪҜ件жҖҺд№Ҳи®ҫзҪ®дёӯж–ҮжЁЎејҸпјҲж°ҙжһң...
- е№ҙиҪ»дәәжңҖи®ЁеҺҢзҡ„еҫ®дҝЎиЎЁжғ…Top10пјҡ...
- й’ўеҺӮж–—иҪ®жңәж”№дёәж— зәҝжҺ§еҲ¶пјҢе·ҘеҺӮе№ҙ...
- RжҳҹBз«ҷеҸ‘еёғгҖҠиҚ’йҮҺеӨ§й•–е®ўгҖӢдёӯж–Үе®Ј...
- дёӯе…ҙе°ҸйІң50ејҖе”®пјҡеҗҙдә¬д»ЈиЁҖ е”®...
- 8жңҲ8ж—ҘеұұдёңжёҜеҸЈз„ҰзӮӯеёӮеңәд»·ж јжҡӮзЁі
- 2023зҰҸе»әзҰҸе·һеёӮйј“жҘјеҢә第дәҢж¬ЎзӨҫеҢә...
- жөҷжұҹжё©е·һе№ійҳіпјҡж ‘е…ёиҢғеҲҮе®һжҸҗеҚҮйЈҹ...
- зәўзұіNote 12еұҸ幕иҙЁйҮҸеҰӮдҪ•
- ж–°жөӘеҫ®еҚҡж Үеҝ—еӣҫзүҮlogoпјҲж–°жөӘеҫ®еҚҡ...
- дёҖеҠ Ace 2 ProжҲ–иҒ”еҠЁзҫҺдҫқзӨјиҠҪ...
- зәўзұіK60иҮіе°ҠзүҲжҖ§иғҪејәжӮҚ з»ӯиҲӘ...
- еҶңдёҡ银иЎҢиҚЈиҺ·“дёӯеӣҪдјҒдёҡзӨҫдјҡиҙЈд»»...
- еӣҪ家ж–Үзү©еұҖеӣһеә”зӨҫдјҡе…іеҲҮ е°Ҷ继з»ӯ...
- дёӯе…ҙйҖҡи®Ҝеӣһеә”иӮЎзҘЁй—Әеҙ©пјҡе…¬еҸёз»ҸиҗҘ...
- 8жңҲ8ж—Ҙе…Ёж°‘еҒҘиә«ж—ҘпјҢжҳҢе№іиҝҷдәӣдҪ“иӮІ...
- йҳҝйҮҢдә‘Serverlessеә”з”Ёеј•ж“ҺSAE2.0...
- й”ҷиҝҮеҗҺжӮ”з»Ҳиә« 4299е…ғжҠўиҙӯз”өи„‘
- жө·е°”15.6иӢұеҜёз¬”и®°жң¬йҷҗж—¶дјҳжғ
- е…ғе®Үе®ҷж–Үж—…дёҚйЈҳпјҢеҺҰй—Ёйј“жөӘеұҝеңЁзӢӮйЈҷ
- жІёи…ҫ 251 еӨ©пјҢи®ҝи°Ҳиҝ‘зҷҫдҪҚд»Һдёҡ...
- еҚҺдёәMateBook D 15.6иӢұеҜёз¬”и®°жң¬3799е…ғ
- зҘһз§ҳдјҳжғ пјҒеҚҺзЎ•еӨ©йҖү 4 Plusй”җ...
- дёҖең°е®Јеёғиҝһдј‘5еӨ©пјҒ
- з”·еӯҗж°ҙеЎҳжҚүй»„йіқж‘ёеҮәдёҖжһҡзӮ®еј№пјҢеҗ“...
- жі°е®үеёӮж·ұе…ҘејҖеұ•“дёүиҒҡдёүж–°” еҠ ...
- жі°еӣҪдёәжі°е…ҡдёҺиҮӘиұӘжі°е…ҡе®ЈеёғиҒ”еҗҲз»„...
- жҖқеҝөзҡ„ж•…д№Ў.иҲ’ж„Ҹ
